Laporan: Nvidia dan pelanggan utama akhirnya mengatasi masalah penerapan chip Blackwell

Satu tahun yang lalu, CEO Nvidia Jensen Huang memberi tahu para analis bahwa karena kompleksitas chip AI generasi baru Blackwell yang meningkat secara signifikan, proses transisi pelanggan dari chip server AI generasi sebelumnya ke chip ini sangat “menantang”. Ia mengatakan, demi meningkatkan performa chip, “semua aspek seperti casing server, arsitektur sistem, konfigurasi perangkat keras, hingga sistem daya harus disesuaikan”.
Faktanya, bagi sejumlah pelanggan inti Nvidia, mendorong penerapan server Blackwell dan operasionalisasi dalam skala besar sempat menjadi tantangan besar. Menurut dua karyawan Nvidia yang melayani OpenAI dan klien besar lainnya, serta seorang karyawan Meta yang terlibat langsung dalam penanganan masalah terkait, sepanjang tahun lalu OpenAI, Meta Platforms, dan penyedia layanan cloud yang mereka ajak kerja sama selalu kesulitan membangun dan menggunakan sistem semacam itu secara stabil. Mereka semua mengungkapkan bahwa, dibandingkan dengan chip AI Nvidia sebelumnya, setelah menerima chip baru Blackwell, pelanggan bisa menyelesaikan deployment dan mulai menggunakan dalam hitungan minggu saja.
Berbagai tantangan yang dihadapi pelanggan inti Nvidia dalam menggunakan chip seri Blackwell (terutama model Grace Blackwell) tampaknya tidak memberikan dampak serius terhadap bisnis raksasa chip ini. Nvidia tetap menjadi perusahaan dengan nilai pasar tertinggi di dunia, yakni 4,24 triliun dolar AS, dan kini sebagian besar masalah teknis yang menghambat deployment cepat dalam skala besar oleh pelanggan utama telah diselesaikan.
Namun, jika chip baru Nvidia di masa mendatang masih menghadapi masalah deployment serupa, pesaing seperti Google mungkin berpeluang menonjol—selama mereka bisa membantu pelanggan melakukan deployment chip secara besar-besaran dan lebih cepat untuk mendukung pengembangan teknologi AI mutakhir. Masalah semacam ini juga dapat menyebabkan penyedia layanan cloud yang gagal melakukan deployment chip secara skala besar mengalami penurunan profit, serta memperlambat kemajuan perusahaan AI yang mengandalkan chip tersebut dalam mengembangkan model AI yang lebih canggih.
Isi artikel ini didasarkan pada wawancara dengan karyawan Nvidia, karyawan Meta, staf penyedia layanan cloud yang menggunakan chip Nvidia, serta mitra yang menyediakan layanan instalasi chip Nvidia untuk pusat data.
Bagi pelanggan seperti OpenAI dan Meta, ketidakmampuan membangun cluster chip dalam skala yang diharapkan akan membatasi kemampuan mereka untuk melatih model AI berskala lebih besar. Menurut seorang karyawan Nvidia, meskipun pelanggan Nvidia tidak mengeluh secara terbuka tentang masalah ini, beberapa di antaranya telah menyampaikan ketidakpuasan secara pribadi kepada perwakilan Nvidia.
Untuk menutupi kerugian yang dialami pelanggan akibat kendala ini, menurut seorang eksekutif penyedia layanan cloud dan seorang karyawan Nvidia yang terlibat dalam negosiasi tersebut, tahun lalu Nvidia menawarkan sebagian pengembalian uang dan diskon kepada pelanggan terkait masalah chip Grace Blackwell.
Eksekutif Nvidia dan penyedia layanan cloud menyatakan, masalah utama terjadi pada server yang menghubungkan 72 chip Grace Blackwell—desain seperti itu memang bertujuan untuk meningkatkan kecepatan komunikasi antar chip secara signifikan dan memungkinkan operasi sistem secara kolaboratif. Server ini dapat terhubung dengan server lain untuk membentuk cluster berskala sangat besar, menyediakan daya komputasi untuk pelatihan intensif model AI.
Seorang juru bicara Nvidia mengatakan, perusahaan telah menanggapi keraguan terkait lambatnya deployment sistem Grace Blackwell pada tahun 2024, dan pada saat itu memberikan pernyataan ke majalah The Information bahwa sistem ini adalah “komputer paling canggih sepanjang sejarah”, yang penerapannya memerlukan “rekayasa bersama dengan pelanggan”.
Pernyataan itu juga menyebutkan: “Nvidia tengah menjalin kerja sama mendalam dengan penyedia layanan cloud terkemuka, di mana tim mereka telah menjadi bagian tak terpisahkan dari sistem dan proses rekayasa kami, dan iterasi rekayasa terkait adalah fenomena normal di industri serta bagian dari yang kami harapkan.”
Eksekutif infrastruktur OpenAI, Sachin Katti, menyatakan bahwa kerja sama startup ini dengan Nvidia “sepenuhnya mendukung roadmap penelitian dan pengembangan kami sesuai rencana. Kami sedang memanfaatkan semua chip Nvidia yang tersedia secara penuh dalam pelatihan dan inferensi model, yang juga mempercepat iterasi dan peluncuran produk—berbagai model terbaru yang kami rilis adalah bukti terbaiknya”.
Juru bicara Meta menolak berkomentar terkait hal ini.
Nyeri Pertumbuhan
Ada tanda-tanda bahwa Nvidia telah belajar dari masalah deployment kali ini. Perusahaan tidak hanya mengoptimalkan sistem Grace Blackwell yang ada, tetapi juga melakukan peningkatan pada server berbasis chip generasi baru Vera Rubin yang akan diluncurkan akhir tahun ini.
Menurut dua orang yang terlibat dalam desain chip, tahun lalu Nvidia merilis versi upgrade chip Grace Blackwell yang performanya lebih baik, untuk memastikan stabilitas operasionalnya melebihi produk generasi pertama. Mereka menyebutkan, chip upgrade bernama GB300 ini telah mengalami peningkatan dalam kemampuan pendinginan, material inti, dan kualitas konektornya.
Seorang karyawan Meta yang mengetahui situasi menyatakan bahwa insinyur Meta yang pernah mengalami masalah teknis dengan sistem Grace Blackwell generasi pertama menemukan bahwa kesulitan integrasi chip pada versi baru berkurang drastis. Sementara itu, seorang karyawan Nvidia yang melayani OpenAI mengatakan bahwa beberapa pelanggan, termasuk OpenAI, telah mengubah pesanan chip Grace Blackwell yang belum dikirim dan beralih untuk membeli produk upgrade tersebut.
Pada musim gugur lalu, Nvidia mengungkapkan kepada investor bahwa sebagian besar pendapatan dari chip seri Blackwell kini berasal dari server Grace Blackwell yang telah dioptimalkan, dan perusahaan berencana melakukan pengiriman massal server model ini tahun ini.
Perusahaan xAI milik Elon Musk, yang sangat bergantung pada chip Nvidia, tampaknya menjadi yang terdepan dalam penerapan server Grace Blackwell. Pada Oktober lalu, perusahaan ini telah menyelesaikan deployment sekitar 100.000 chip di pusat data Memphis dan mulai beroperasi, meski belum jelas apakah strategi deployment ini membawa hasil yang lebih baik.
Bangun Dulu, Uji Belakangan
Tujuan pengembangan chip Blackwell oleh Nvidia sangat jelas: membantu pelanggan melatih model AI dengan skala dan efisiensi biaya yang jauh lebih baik daripada chip AI generasi sebelumnya.
Dalam server Nvidia generasi sebelumnya, pelanggan hanya dapat menghubungkan maksimal 8 chip, dan kecepatan komunikasi antar chip masih lambat. Sementara itu, inti desain chip seri Blackwell adalah menghubungkan 72 chip Grace Blackwell dalam satu server, mengurangi volume transfer data antar server, sehingga membebaskan sumber daya jaringan pusat data dan mendukung pelatihan serta operasional model AI berskala lebih besar.
Menurut seorang karyawan Oracle yang pernah terlibat dalam pembangunan cluster chip, dengan cara ini, pembangunan cluster chip berskala besar juga dapat meningkatkan kualitas model AI yang dilatih, dan desain sistem ini memang bertujuan mengurangi kegagalan perangkat keras yang sering terjadi saat pelatihan model.
Namun, desain baru Nvidia ini juga memiliki kelemahan. Integrasi chip dalam jumlah besar secara erat berarti kegagalan satu chip saja bisa memicu efek domino, menyebabkan cluster ribuan chip lumpuh atau proses terganggu. Menurut tiga orang yang pernah mengalami kegagalan semacam ini, perusahaan perlu mengeluarkan biaya ribuan hingga jutaan dolar untuk memulai ulang proses pelatihan dari node penyimpanan terakhir.
Penerapan sistem Grace Blackwell dari Nvidia memang mengalami banyak hambatan sejak awal. Pada musim panas 2024, cacat desain chip menyebabkan penundaan produksi massal, dan berbagai masalah mulai muncul. Satu tahun lalu, setelah pengiriman perdana chip Blackwell ke pelanggan, lemari server mengalami masalah overheating dan koneksi berulang kali, sehingga Microsoft, Amazon Web Services, Google, Meta, dan pelanggan inti lainnya mengurangi pesanan dan beralih membeli chip generasi sebelumnya.
Beberapa karyawan penyedia layanan cloud yang memesan chip Grace Blackwell menyatakan mereka yakin Nvidia sudah melakukan pengiriman ke pelanggan sebelum perangkat lunak dan perangkat keras terkait sepenuhnya di-debug.
Namun, seorang mantan eksekutif Nvidia membela strategi perusahaan, mengatakan bahwa masalah “nyeri pertumbuhan” yang dialami server Grace Blackwell dengan 72 chip terintegrasi justru menunjukkan keberanian Jensen Huang untuk menembus batas teknologi, bukan sekadar mengejar operasi yang aman. Baik karyawan Nvidia saat ini maupun yang sudah keluar sepakat bahwa mengharapkan Nvidia bisa secara akurat memprediksi performa chip dalam skenario deployment skala besar pelanggan seperti OpenAI dan Meta memang tidak realistis.
Ada pula tanda bahwa OpenAI kini telah berhasil menggunakan server Nvidia dengan 72 chip terintegrasi secara luas. Pada hari Kamis pekan ini, OpenAI mengumumkan bahwa pengembangan model kode AI terbaru mereka, GPT-5.3-Codex, “sepenuhnya didukung desain sistem khusus ini, menyediakan daya pelatihan dan mendukung deployment secara penuh”.
Pendapatan Tertunda
Menurut para eksekutif dari dua penyedia layanan cloud, sepanjang tahun lalu, keterlambatan deployment chip menyebabkan sebagian mitra cloud OpenAI mengalami kerugian—perusahaan-perusahaan ini telah menginvestasikan dana besar untuk chip Grace Blackwell, berharap chip bisa segera digunakan dan modal bisa kembali, namun penyedia cloud hanya bisa mendapatkan penghasilan setelah pelanggan mulai memakai chip.
Seorang eksekutif penyedia layanan cloud yang terlibat dalam negosiasi menyatakan bahwa untuk mengurangi tekanan keuangan, beberapa penyedia layanan cloud tahun lalu telah mencapai kesepakatan diskon dengan Nvidia, sehingga dapat membayar biaya chip hanya berdasarkan persentase kecil dari volume penggunaan aktual.
Selain itu, menurut seorang karyawan Nvidia dan staf mitra manufaktur Nvidia, Nvidia juga memberikan pengembalian dana kepada beberapa pelanggan yang mengembalikan server.
Ketika penyedia layanan cloud meluncurkan teknologi baru, mereka biasanya harus menanggung biaya terlebih dahulu, baru bisa memperoleh pendapatan setelah pelanggan mulai menggunakan perangkat keras tersebut, sehingga margin keuntungan pada tahap ini biasanya rendah. Sebuah dokumen menunjukkan bahwa dalam tiga bulan yang berakhir Agustus tahun lalu, Oracle mengalami kerugian hampir 100 juta dolar AS karena menyewakan chip seri Blackwell—penyebab utamanya adalah jeda waktu yang jelas antara penyelesaian debugging server oleh Oracle dan pengiriman ke pelanggan, serta waktu mulai digunakan dan pembayaran sewa oleh pelanggan seperti OpenAI.
Dokumen presentasi internal yang disiapkan untuk eksekutif cloud Oracle menunjukkan bahwa margin kotor bisnis sewa chip Grace Blackwell negatif, terutama dipengaruhi oleh masalah deployment chip di pusat data OpenAI di Abilene, Texas, serta siklus penerimaan pelanggan yang tertunda.
Setelah itu, Oracle menginformasikan kepada investor bahwa bisnis cloud AI mereka pada akhirnya akan mencapai margin kotor 30% hingga 40%, dan ekspektasi ini sudah mencakup periode investasi sebelum pusat data online.
Juru bicara Oracle menolak berkomentar terkait hal ini.
Editor: Ding Wenwu
Disclaimer: Konten pada artikel ini hanya merefleksikan opini penulis dan tidak mewakili platform ini dengan kapasitas apa pun. Artikel ini tidak dimaksudkan sebagai referensi untuk membuat keputusan investasi.
Kamu mungkin juga menyukai
Hims membatalkan niat untuk menawarkan kapsul GLP-1 campuran setelah kritik dari FDA
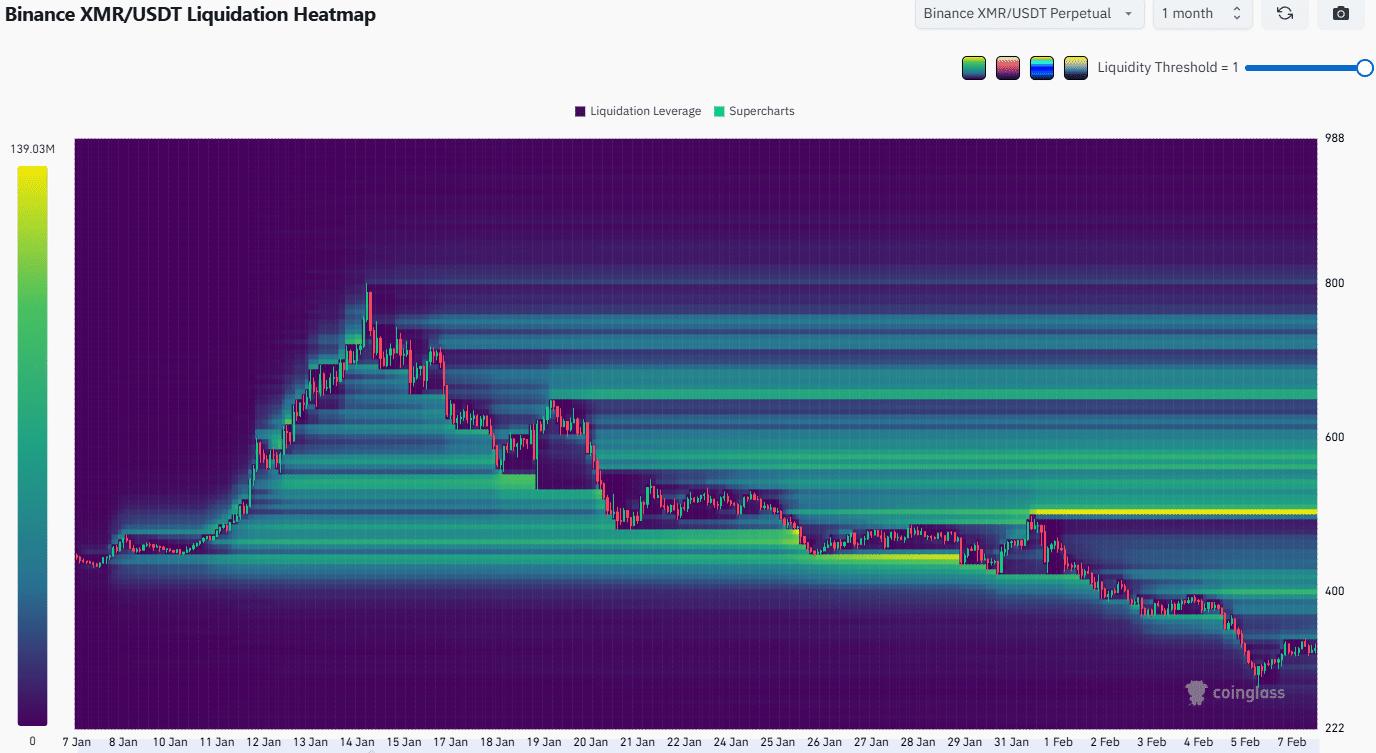
Monero jatuh dari FOMO ke penurunan bebas 63% – Apa selanjutnya untuk XMR?
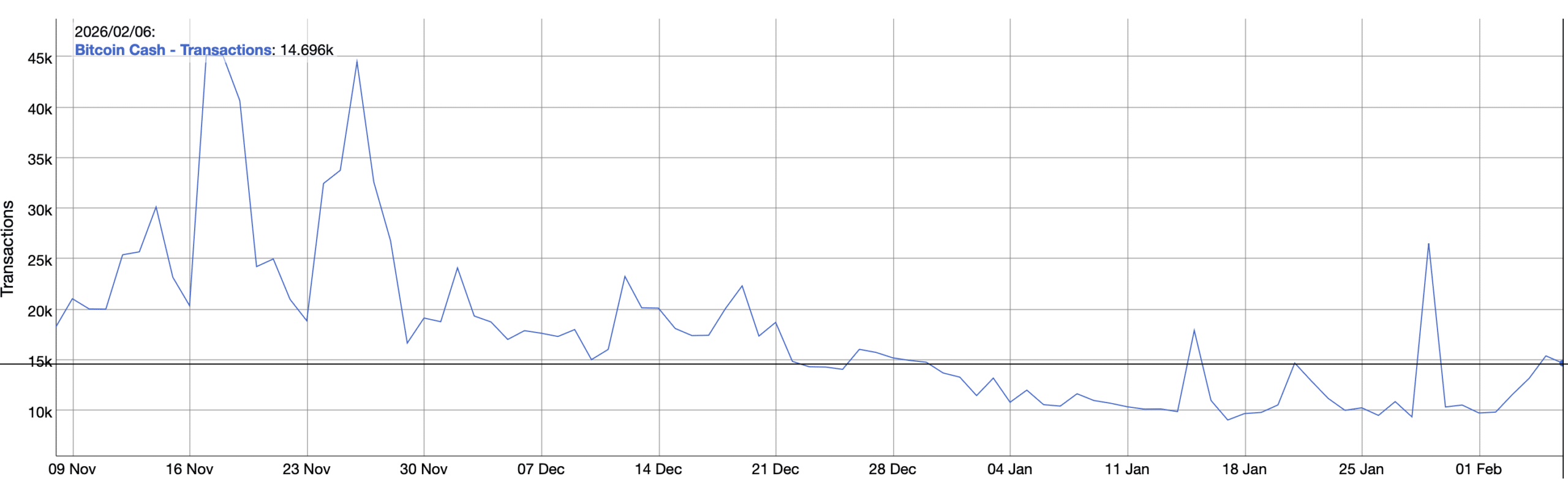
Reli Bitcoin Cash menghadapi UJIAN PENTING – Bisakah BCH bertahan di atas $500?